Pangbai 泰拉记(1)
函数表给了,方便做题
主函数是一个很简单的 flag 异或一个 key,但是在主函数前,有个前置函数,会对 key 进行修改
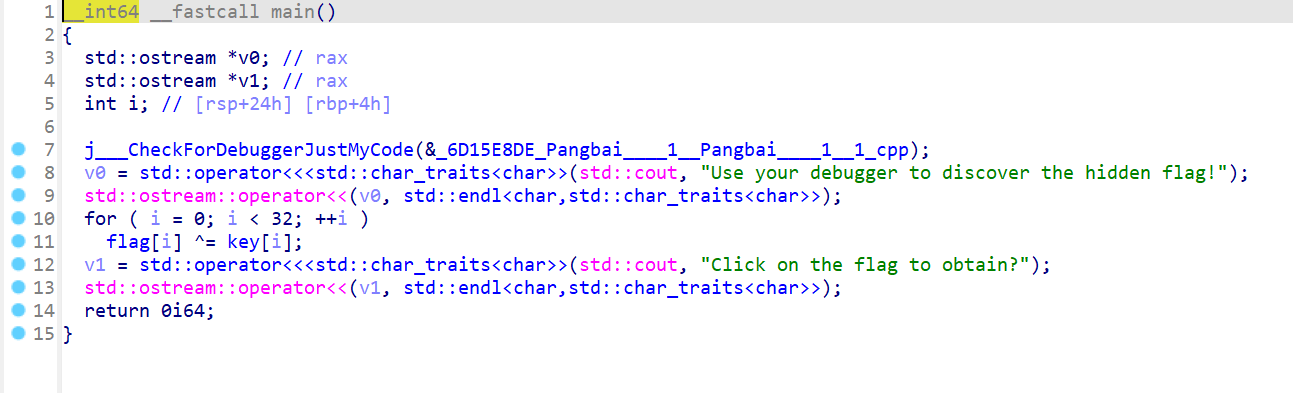
找到前置函数,可以对 key 按 X 进行交叉引用,或者直接在函数表表里找有个 main0
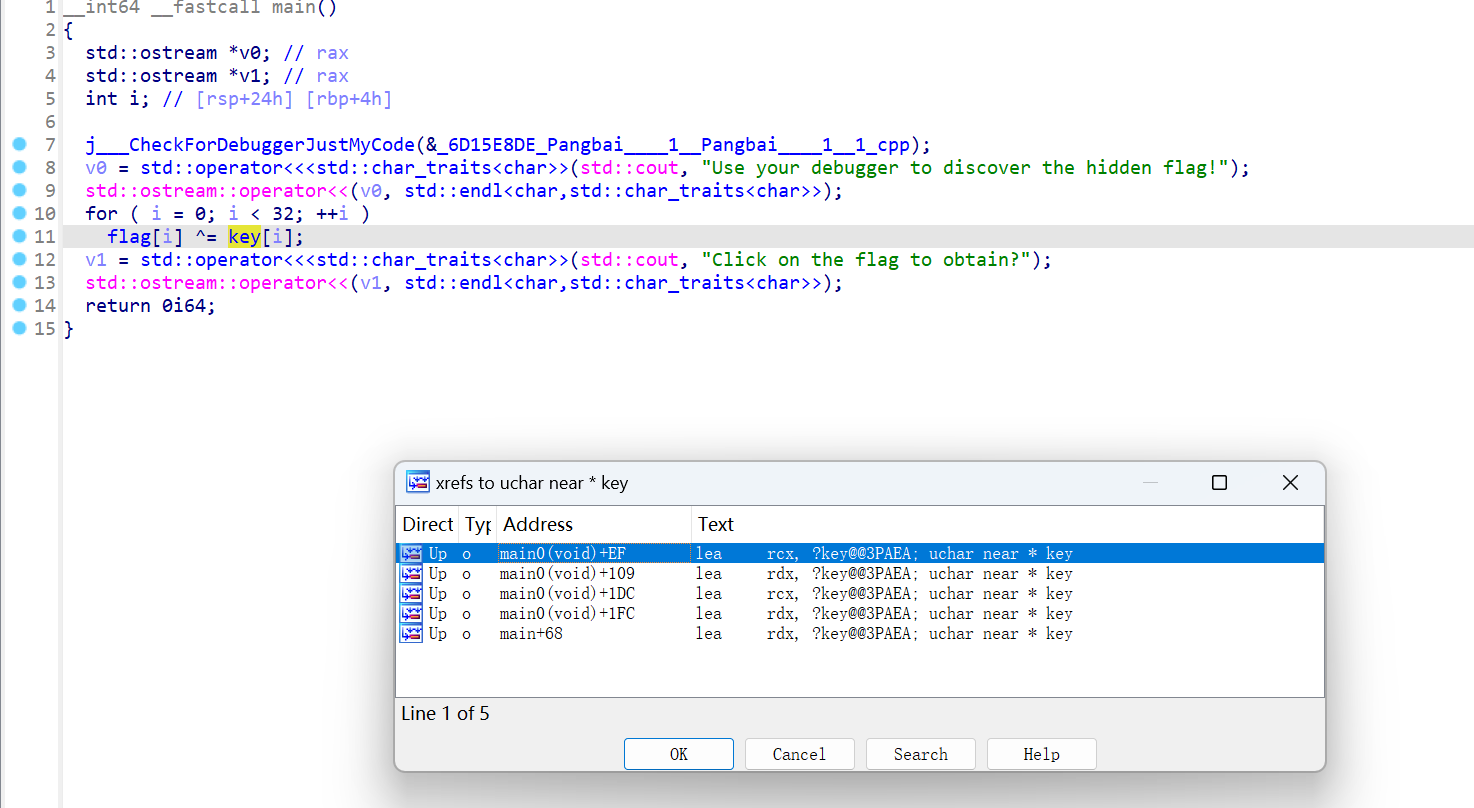
前置函数里写了两个很经典的反调试

逻辑是:当检测到你调试的时候,你的 key 会被异或替换成错误的 key,但是如果你正常运行,key 会被替换异或成正确的 key
- 解法 1:直接把反调试函数
nop掉,不太推荐,对汇编不太熟悉的话会报错 - 解法 2:改跳转(推荐解法)
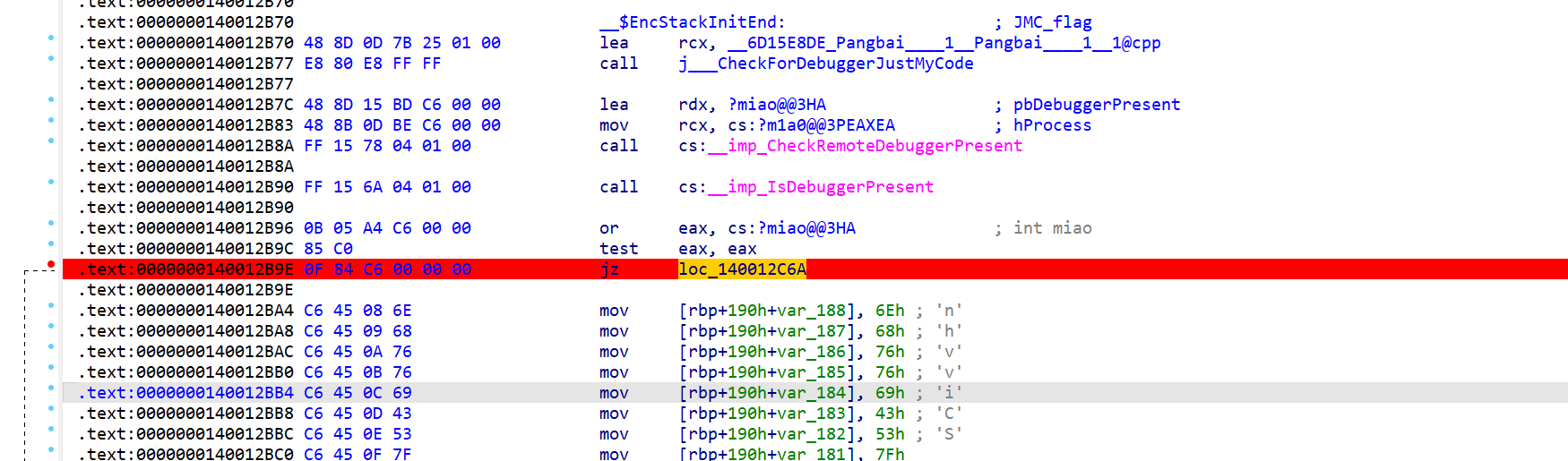 断到这里的时候,改
断到这里的时候,改 jz为jnz或者,改 ZF 寄存器,就可以跳到正确的 key,得到正确的 flag - 解法 3:装自动绕过反调试插件,小幽灵
 得到正确的 flag 和 key,如果还没学到调试的话,其实看逻辑应该也可能解出这题
得到正确的 flag 和 key,如果还没学到调试的话,其实看逻辑应该也可能解出这题
Ezencypt
打开 MainActivity 查看 Onclick 逻辑,Enc enc = new Enc(tx),加密逻辑在 Enc
Enc 的构造函数里进行了第一次加密,代码可以看出是 ECB 模式的 AES,密钥是 MainActivity 的 title.
doEncCheck 函数进行加密数据检查,有 native 标签说明函数是 C 语言编写的,主体在 so 文件。
IDA 打开 so 文件,找到 doEncCheck 的实现
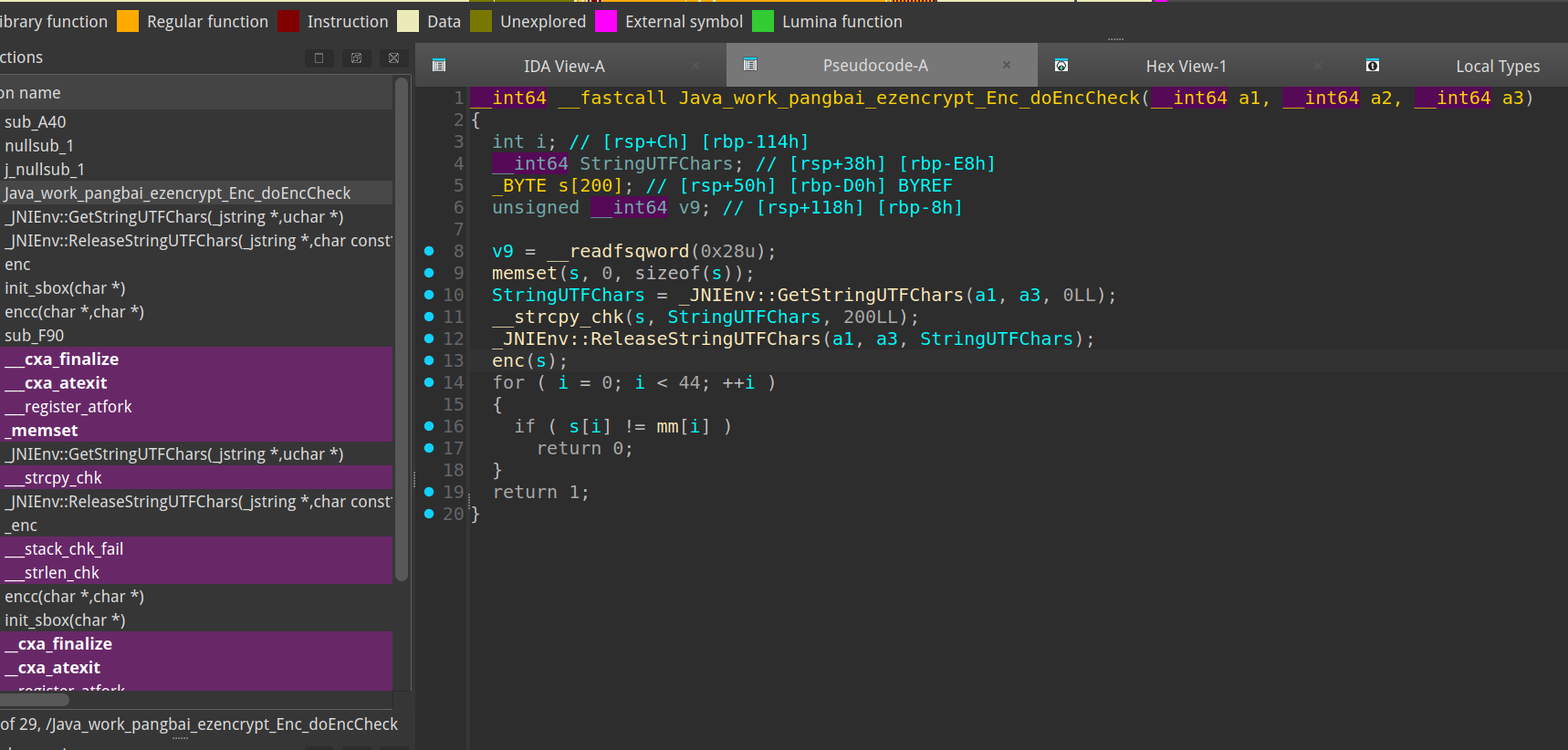
发现数据经过 enc 函数的加密,再在循环里检验
enc 里一个异或加密,一个 RC4,key是 xork
思路全部清楚了,写解密脚本:
C
#include "stdio.h"
#include "string.h"
char xork[] = "meow";
#define size 256
unsigned char sbox[257] = {0};
// 初始化 s 盒
void init_sbox(char *key) {
unsigned int i, j, k;
int tmp;
for (i = 0; i < size; i++) {
sbox[i] = i;
}
j = k = 0;
for (i = 0; i < size; i++) {
tmp = sbox[i];
j = (j + tmp + key[k]) % size;
sbox[i] = sbox[j];
sbox[j] = tmp;
if (++k >= strlen((char *)key)) k = 0;
}
}
// 加解密函数
void encc(char *key, char *data) {
int i, j, k, R, tmp;
init_sbox(key);
j = k = 0;
for (i = 0; i < strlen((char *)data); i++) {
j = (j + 1) % size;
k = (k + sbox[j]) % size;
tmp = sbox[j];
sbox[j] = sbox[k];
sbox[k] = tmp;
R = sbox[(sbox[j] + sbox[k]) % size];
data[i] ^= R;
}
}
void enc(char *in) {
int len = strlen(in);
for (int i = 0; i < len; ++i) {
in[i] ^= xork[i % 4];
}
encc(xork, in);
}
int main() {
unsigned char mm[] = {0xc2, 0x6c, 0x73, 0xf4, 0x3a, 0x45, 0x0e, 0xba, 0x47, 0x81, 0x2a,
0x26, 0xf6, 0x79, 0x60, 0x78, 0xb3, 0x64, 0x6d, 0xdc, 0xc9, 0x04,
0x32, 0x3b, 0x9f, 0x32, 0x95, 0x60, 0xee, 0x82, 0x97, 0xe7, 0xca,
0x3d, 0xaa, 0x95, 0x76, 0xc5, 0x9b, 0x1d, 0x89, 0xdb, 0x98, 0x5d};
enc(mm);
for (size_t i = 0; i < 44; i++) {
putchar(mm[i]);
}
puts("");
}将 so 层解密后的数据(输出)用 CyberChef 进行 Base64 和 AES 解密就行了:Recipe.
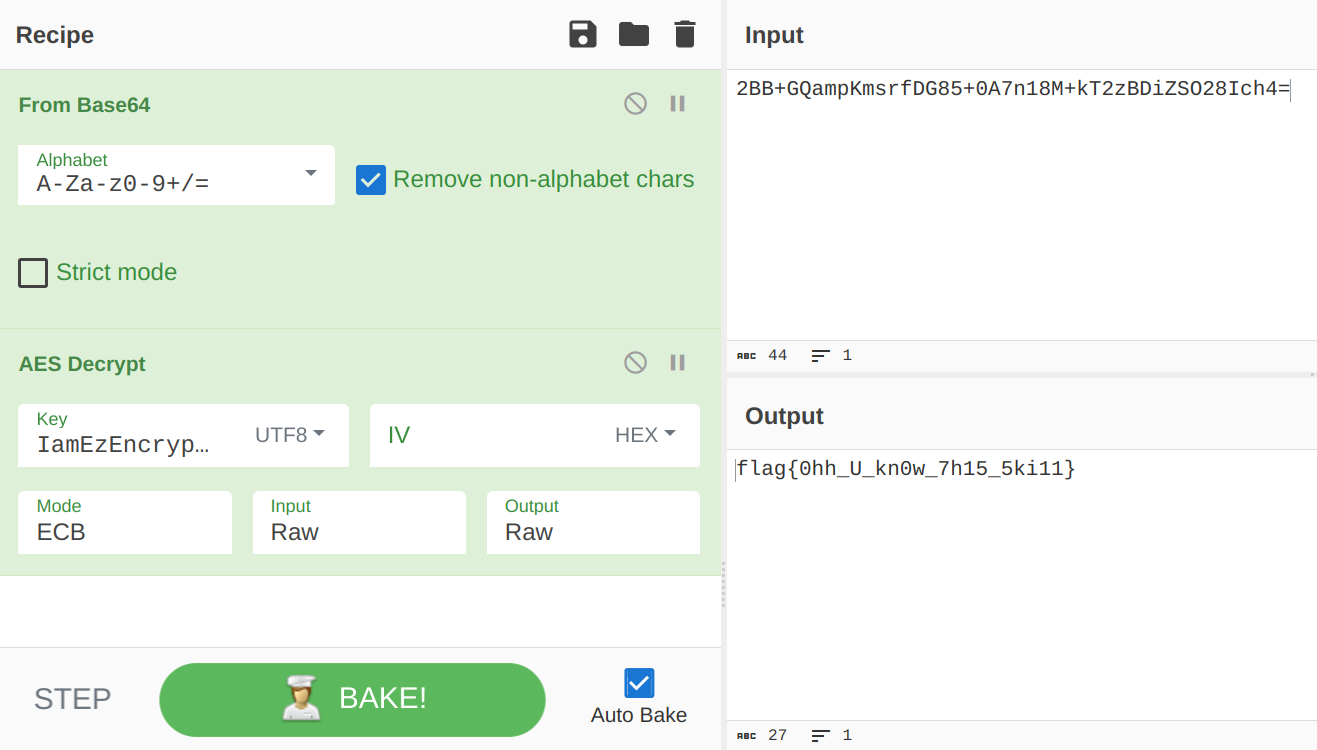
脱壳
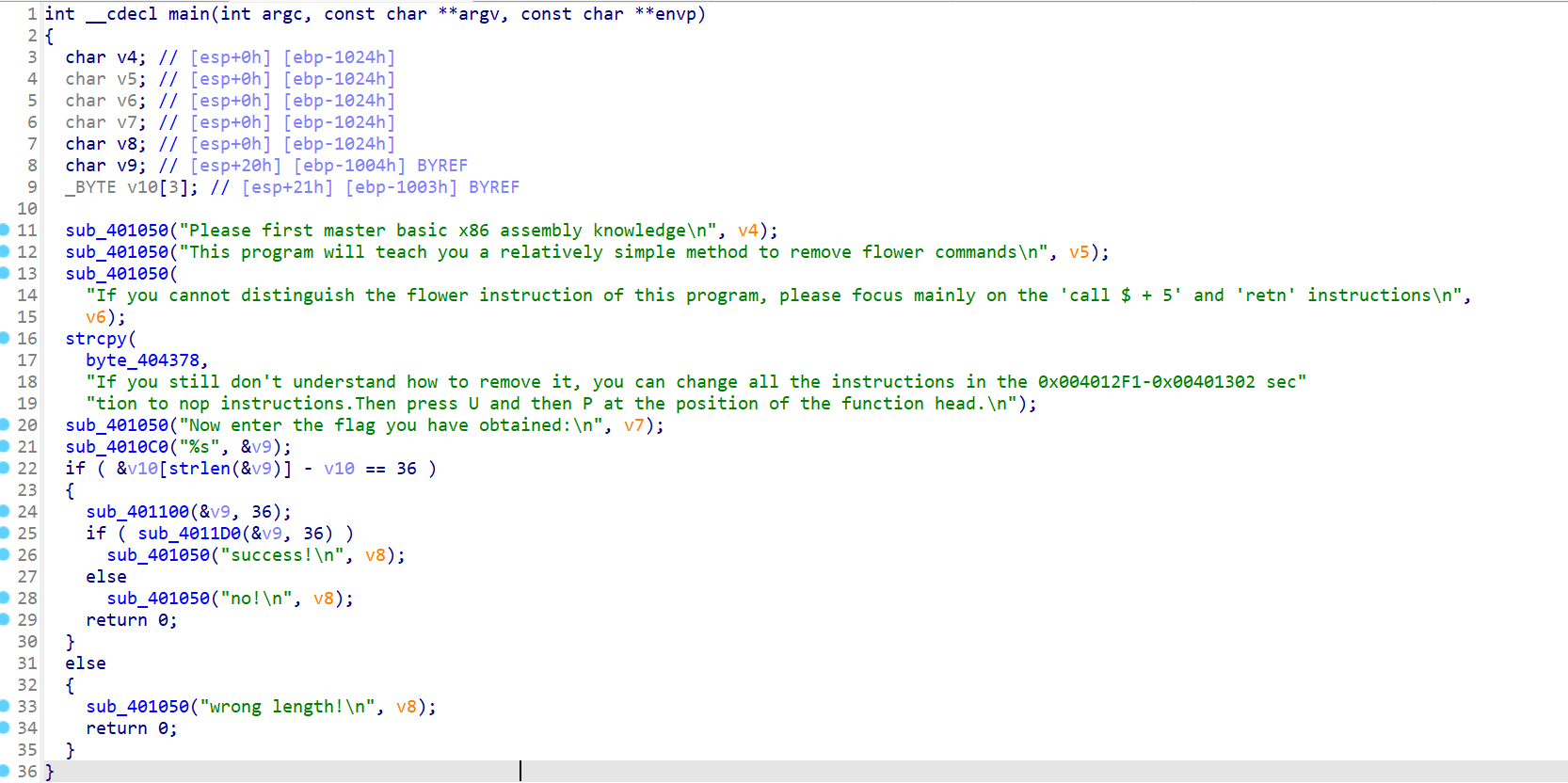
使用 IDA 查看文件,发现主函数很复杂。
这时根据文件的名称和提示,和 UPX 相关联。直接搜索 UPX,可以得知它是可执行程序文件压缩器,是一种压缩壳。在程序启动时先执行 UPX 的代码,把压缩后的原文件解压后,再把控制流转到原文件。然后这里可以使用 DIE 进行查看,特征也显示为 UPX.
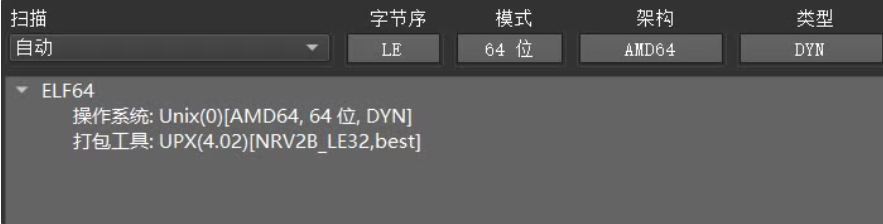
因此可以采用工具尝试能不能直接脱壳,或者使用手动脱壳的办法进行脱壳。
因为这里没有进行更改,所以可以直接使用工具 https://github.com/upx/upx/releases/ 进行脱壳,然后发现文件的体积变大了。
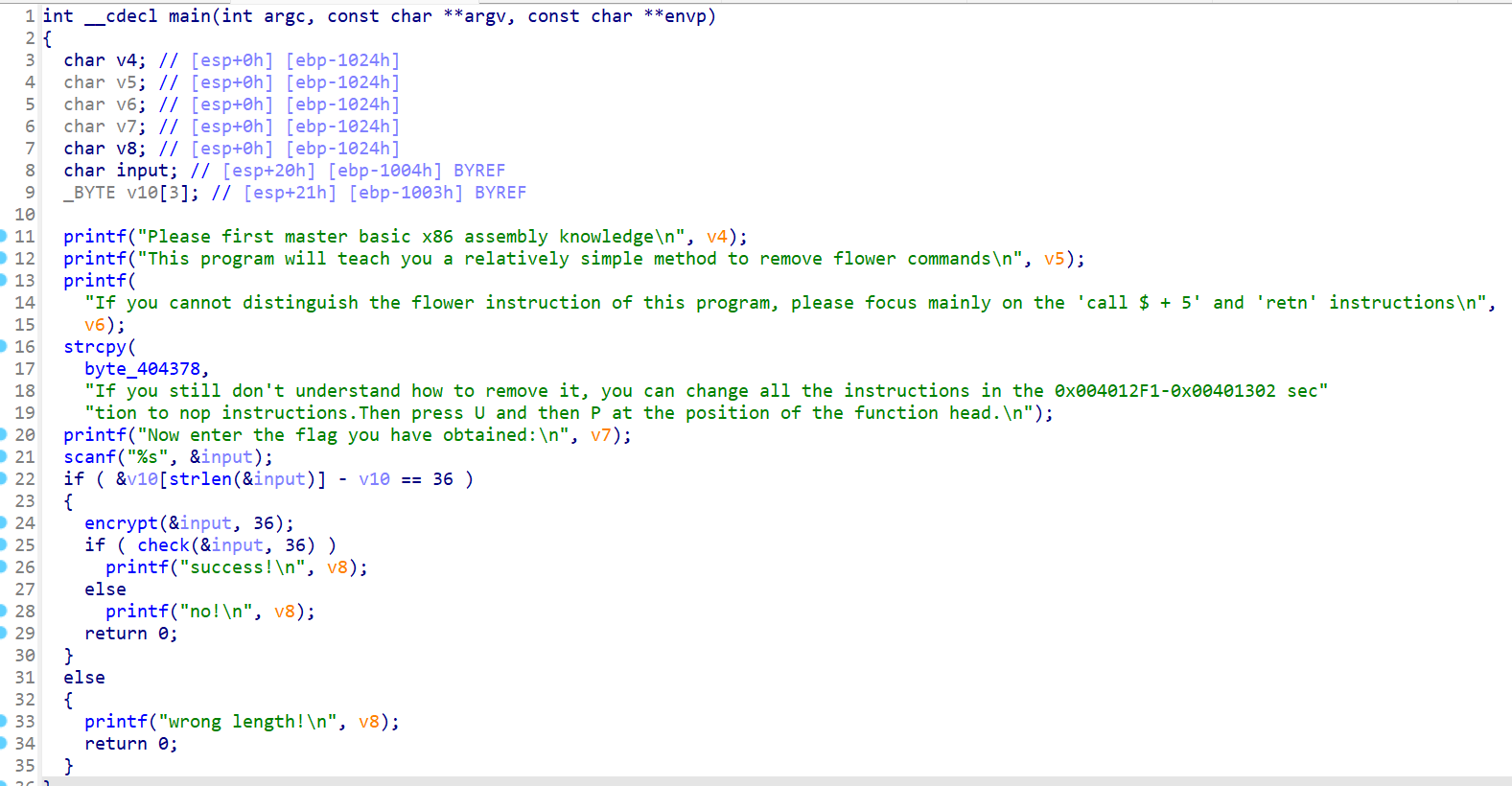
再次使用 IDA 打开脱壳后的程序,发现主函数逻辑很清晰,反汇编的结果也很明确了。
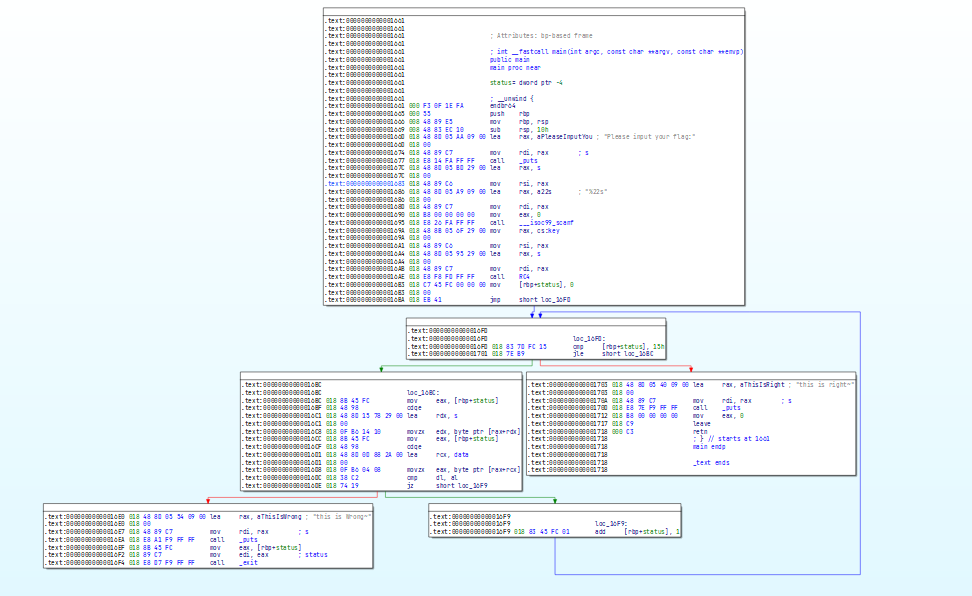
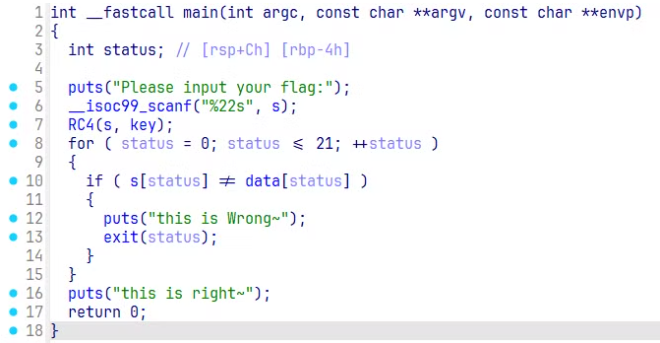
分析
查看这里的 main 函数,发现提示很明确。这里首先通过 __isoc99_scanf 输入内容,利用 %22s 和后续 for 循环中的比较,也提示输入的 flag 长度是 22 字节。然后后面输入 s 和 key 经过了 RC4 的函数,然后把输入 s 和 data 进行比较。
直接搜索 RC4,查阅相关文章,可以得知它是一种流加密算法,它通过字节流的方式依次加密明文中的每一个字节,解密的时候也是依次对密文中的每一个字节进行解密。这里直接点击 RC4 函数,查看其内部是怎么实现的。
在下面可以看到 RC4 函数的实现,它实现调用 init_sbox 函数对于 a2,也就是上面从 main 函数传入的 key 进行一系列处理,然后获取 a1,也就是从 main 函数传入的输入 s,然后在 for 循环中,循环遍历 a1 的每一位,然后使用一个异或进行处理。
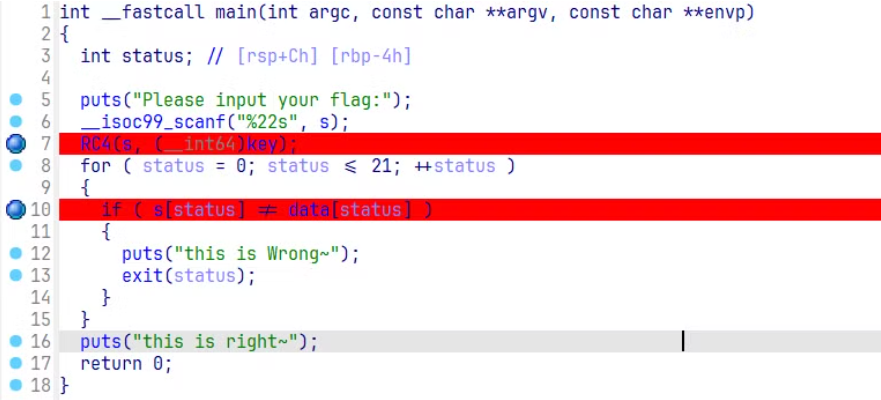
因此我们可以理清楚这个程序的逻辑,我们首先进行了输入,然后程序将我们的输入和内置的密钥及进行 RC4 加密,然后将加密的结果和内置的数据进行比较,如果一样的话,说明我们的输入是正确的。
因此分别点击 main 函数中的 key 和 data 变量,找到了内置的密钥和比对密文,之后就可以写脚本获取 flag 了。
点击 key 一直进行寻找发现了密钥 NewStar.

点击 data 发现这里没有值。
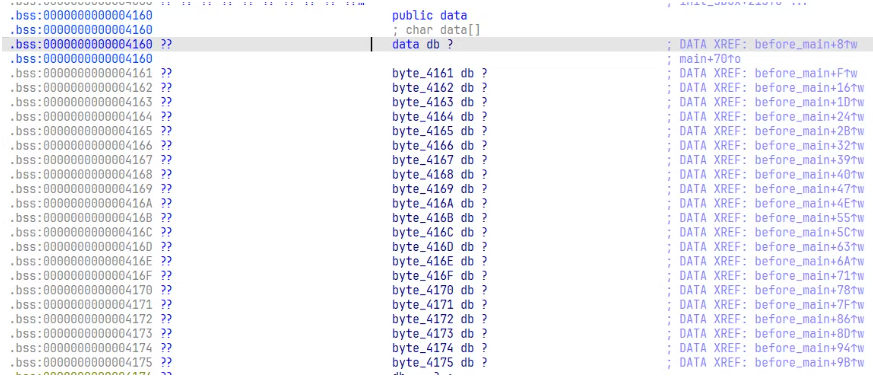
然后对 data 按 x 进行交叉引用,发现存在另外的函数也用到了 data 这个数据。
直接点击这个使用 data 数据的函数 before_main 中,可以发现这里对 data 进行了赋值操作。
这里再次交叉引用 before_main 函数,可以发现它在 .init_array 段被调用。这个段里存放着的是在 main 函数执行前执行的代码,可以搜索相关资料进一步掌握。这里只需要知道它是在 main 函数之前被调用的,那么它就是最后进行比对的密文,我们直接拿出来就行。
方法一
既然已经获取了密文和密钥,那么我们完全可以套用 RC4 的算法来解密。因为 RC4 是流密码,它的本质就是异或,而 a ^ b = c,c ^ b = a,由此可以直接把内置的密文作为输入,然后使用算法进行解密。
C
#include <stdio.h>
#include <string.h>
unsigned char sbox[256] = {0};
const unsigned char* key = (const unsigned char*)"NewStar";
unsigned char data[22] = {-60, 96, -81, -71, -29, -1, 46, -101, -11, 16, 86,
81, 110, -18, 95, 125, 125, 110, 43, -100, 117, -75};
void swap(unsigned char* a, unsigned char* b) {
unsigned char tmp = *a;
*a = *b;
*b = tmp;
}
void init_sbox(const unsigned char key[]) {
for (unsigned int i = 0; i < 256; i++) sbox[i] = i;
unsigned int keyLen = strlen((const char*)key);
unsigned char Ttable[256] = {0};
for (int i = 0; i < 256; i++) Ttable[i] = key[i % keyLen];
for (int j = 0, i = 0; i < 256; i++) {
j = (j + sbox[i] + Ttable[i]) % 256;
swap(&sbox[i], &sbox[j]);
}
}
void RC4(unsigned char* data, unsigned int dataLen, const unsigned char key[]) {
unsigned char k, i = 0, j = 0, t;
init_sbox(key);
for (unsigned int h = 0; h < dataLen; h++) {
i = (i + 1) % 256;
j = (j + sbox[i]) % 256;
swap(&sbox[i], &sbox[j]);
t = (sbox[i] + sbox[j]) % 256;
k = sbox[t];
data[h] ^= k;
}
}
int main(void) {
unsigned int dataLen = sizeof(data) / sizeof(data[0]);
RC4(data, dataLen, key);
for (unsigned int i = 0; i < dataLen; i++) {
printf("%c", data[i]);
}
return 0;
}方法二
上面是写代码进行解密,还可以直接在动调中把输入替换为密文,也可以进行解密。
首先在输入后和比对时按 F2 下断点。
然后进行动调,首先随便输入数据,然后程序在断点处停下(这里颜色改变了,说明断在这里了),输入 s 也显示我们输入的数据。
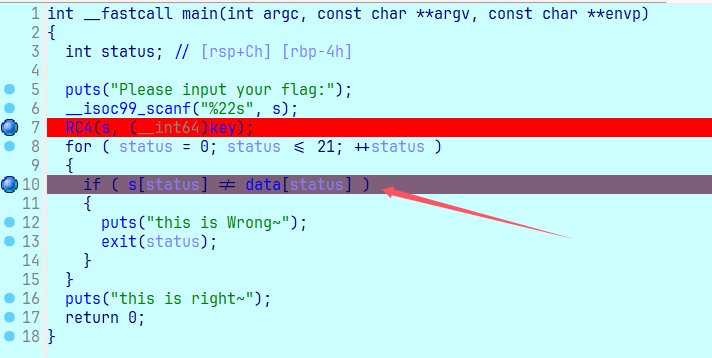
然后先点击 data,找到 data 数据。然后使用 sheift + e 直接取出 data 的相关数据。
然后可以先找到输入 s 的起始地址(0x56201B813040 需要你自己动调时的地址),然后使用 shift + F2 调出 IDAPython脚本窗口,然后使用 python 脚本进行修改,最后点击 Run 进行执行。然后可以发现左侧的输入 s 数据改变了。
python
from ida_bytes import *
# addr = 0x56201B813040 # 这里需要填写自己动调时得到的地址
enc = [0xC4, 0x60, 0xAF, 0xB9, 0xE3, 0xFF, 0x2E, 0x9B, 0xF5, 0x10,
0x56, 0x51, 0x6E, 0xEE, 0x5F, 0x7D, 0x7D, 0x6E, 0x2B, 0x9C,
0x75, 0xB5]
for i in range(22):
patch_byte(addr + i, enc[i])
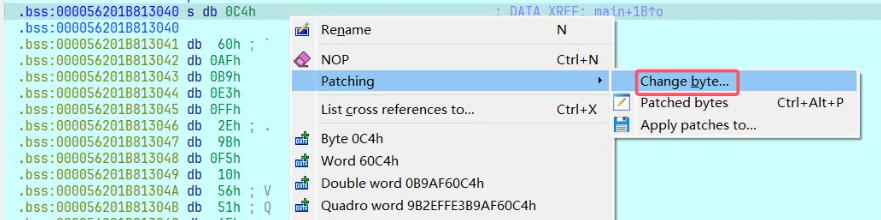
print('Done')或者可以手动 右键 » Patching » Change byte 进行修改。
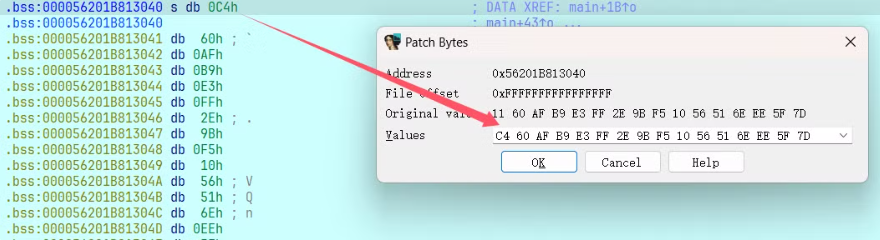
修改完之后,使用快捷键 F9 让程序直接运行,然后它会断在我们之前下的第二个断点处。
这时再看我们的输入 s,会发现它经过 RC4 的再次加密(其实是解密,因为 RC4 是流密码,加密解密的流程一摸一样),呈现出来了 flag.
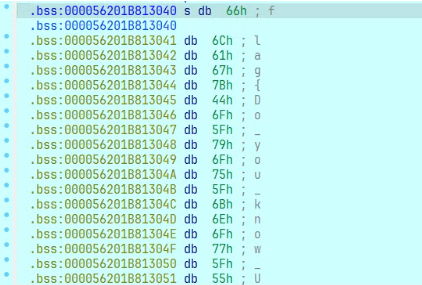
这里按 a 就可以转化为字符串的形式,这个就是最后的 flag 了。

方法三
上面可以知道 RC4 流密码的最后一步就是异或了,那么我们可以在动调的过程中,把这个异或的值拿出来,然后直接把密文和这个异或的数据进行异或即可。
这里先找到 RC4 的加密函数处,在这个最后一步的异或处按 Tab 转化为汇编窗格形式。
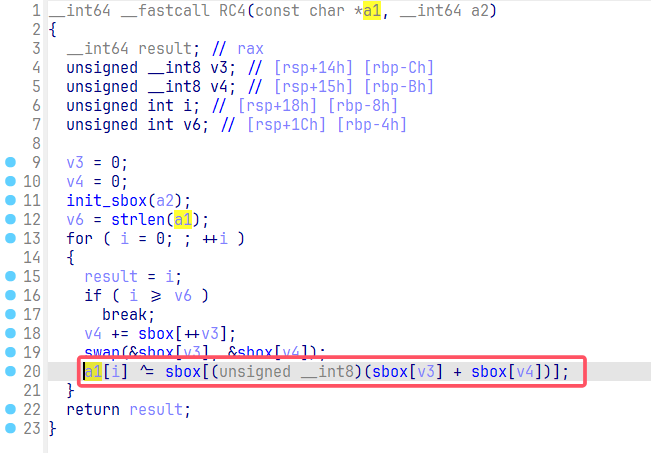
然后在这个汇编的异或处下断点。下面展示了两种汇编代码的视图方式,可以按空格进行相互转换。
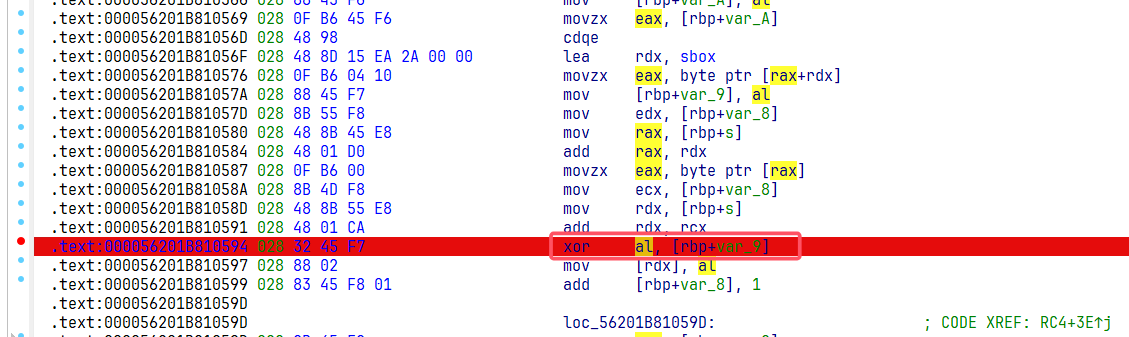

这里不知道两个参数 al 和 [rbp+var_9] 分别代表什么,因此我们可以先直接动调,断在这里的时候再去看看数值。这里动调需要注意,因为 RC4 根据输入的字符个数进行逐个加密的,所以我们需要输入和密文长度相等的字符长度,也就是 22 个字符才可以获得完整的异或值。
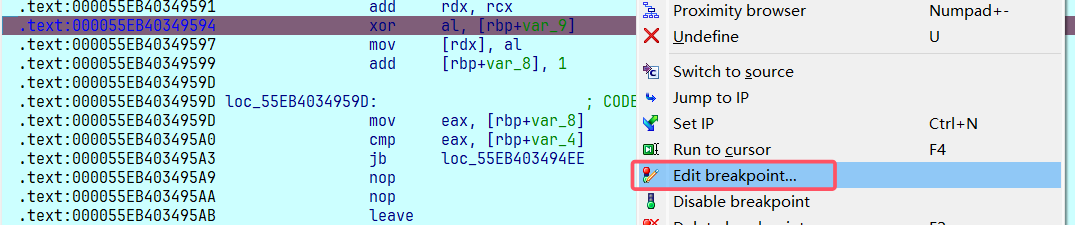
这里发现 al 存储的就是我们的输入数据(我这里输入 22 个字符 a,它的十六进制就是 0x61),然后由此可以知道 [rbp+var_9] 存储的就是需要异或的值。因为它经过了22次循环,所以每次异或的值都可能不一样,但是都只在一个函数中,rbp 的值应该不变,所以可以直接使用条件断点的方式,把 [rbp+var_9] 中的值取出来,或者也可以在下面的 mov [rdx], al 中下条件断点,把异或后的 al 值提取出来

对于在 [rbp+var_9] 下条件断点,首先寻找这个数据的地址。点击进去可以发现数据存储在栈上,当前的数据为 0xA2.
![[rbp+var_9] 的内容](https://blog.jfsmart.top/wp-content/uploads/2024/10/image-175.png)
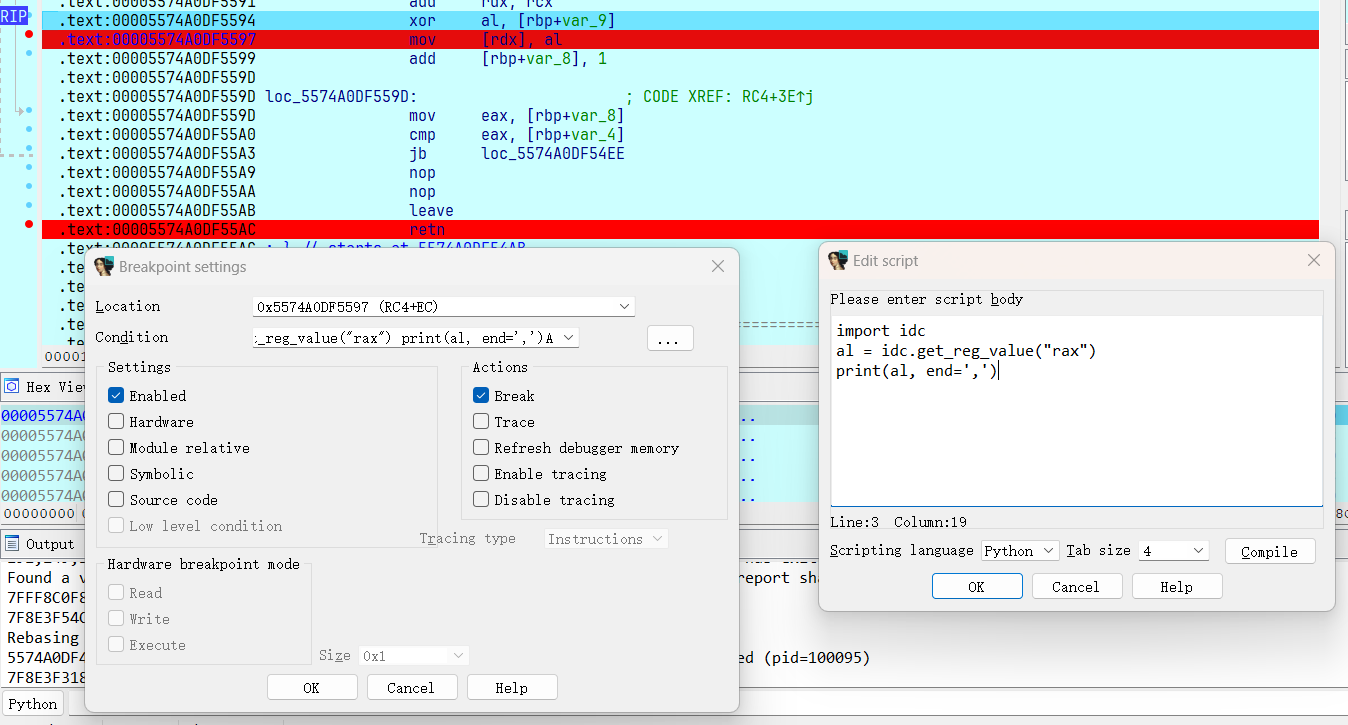
然后回来,在断点处 右键 » Edit breakpoint,然后点击三个点就可调出 IDAPython 的窗口,然后我这里使用 Python 脚本,所以在下面选择语言为 Python.
然后在 Script 中写入 IDAPython 脚本,点击左右两边的 OK 即可。
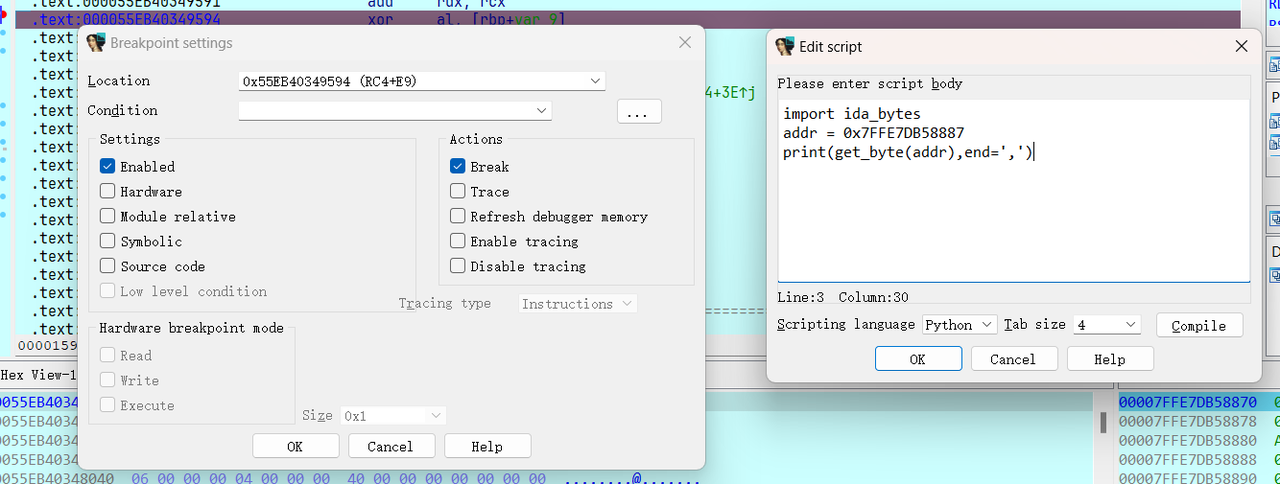
python
import ida_bytes
# addr = 0x7FFE7DB58887 # 这里也是一样,需要自己动调找相应的地址
print(get_byte(addr), end=',')(可以忽略的一步)最后在下面 retn 中下断点,防止 for 循环结束后直接退出,这一步没有太大的必要,只是方便后续的数据查看。
然后最为关键的就是在下面 Output 栏中打印的数据了,可以看到打印出了每次异或的值,但是因为断点的时候第一数据已经运行到了,所以没有第一个数据,但是我们之前查看 [rbp+var_9] 的时候观察到了,所以自己把这个 0xA2 给加上即可。

然后直接把之前获得的密文和这个数据进行异或即可。
python
xor_data = [0xa2, 12, 206, 222, 152, 187, 65, 196, 140,
127, 35, 14, 5, 128, 48, 10, 34, 59, 123, 196, 74, 200]
enc = [0xC4, 0x60, 0xAF, 0xB9, 0xE3, 0xFF, 0x2E, 0x9B, 0xF5, 0x10,
0x56, 0x51, 0x6E, 0xEE, 0x5F, 0x7D, 0x7D, 0x6E, 0x2B, 0x9C,
0x75, 0xB5]
for i in range(len(enc)):
enc[i] ^= xor_data[i]
print(''.join(chr(e) for e in enc))这里我们还可以在下一条语句 mov [rdx], al 中下条件断点
python
import idc
al = idc.get_reg_value("rax")
print(al, end=',')然后得到了假数据经过异或后的数据,然后我们可以利用异或的特性获得 flag.
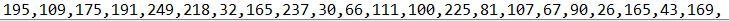
python
input_data = 'aaaaaaaaaaaaaaaaaaaaaa'
after_xor = [195, 109, 175, 191, 249, 218, 32, 165, 237, 30,
66, 111, 100, 225, 81, 107, 67, 90, 26, 165, 43, 169]
enc = [0xC4, 0x60, 0xAF, 0xB9, 0xE3, 0xFF, 0x2E, 0x9B, 0xF5, 0x10,
0x56, 0x51, 0x6E, 0xEE, 0x5F, 0x7D, 0x7D, 0x6E, 0x2B, 0x9C,
0x75, 0xB5]
for i in range(len(enc)):
enc[i] ^= after_xor[i] ^ ord(input_data[i])
print(''.join(chr(e) for e in enc))方法四
这里观察主函数,发现存在 exit 函数,它的功能就是关闭所有文件,终止正在执行的进程,中间的status 参数就是退出码,可以通过 echo $? 来进行获取。
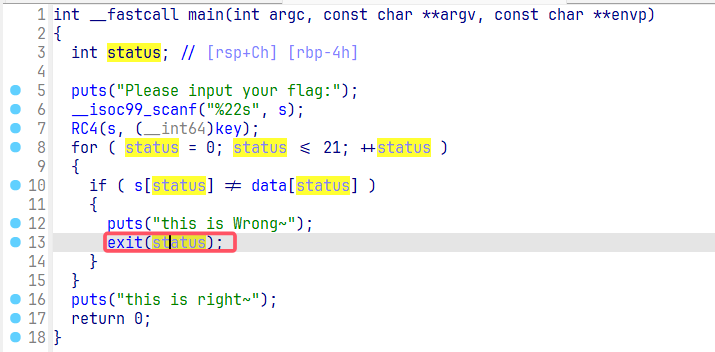
然后观察 status 就是循环的下标,因此可以知道它是单字节判断的,若是某个字节判断错了就直接退出,同时返回第几个字节判断错了。由此根据退出码,我们可以直接进行爆破处理。
这里就是进行爆破的代码,tqdm 只是为了直观显示,可以删去相关代码。
python
from pwn import *
from tqdm import tqdm
context(arch='amd64', os='linux', log_level="error")
str = string.printable
flag = b"a"*22
tmp = 0
for i in tqdm(range(len(flag))):
for j in str.encode():
p = process("./upx")
new_flag = flag[:i] + chr(j).encode() + flag[i+1:]
p.sendafter(b"input your flag:\n", new_flag)
p.wait()
exit_code = p.poll()
p.close()
# 判断退出码是否变化,最后 flag 正确是退出码为 0(return 0),所以需要另外处理
if exit_code > tmp or (exit_code == 0 and tmp != 0):
flag = new_flag
tmp = exit_code
break
print(f"[*] Successfully get the flag : {flag}")然后爆破一分钟左右就跑出结果了。

Ptrace
首先查看 father 文件,可以看到使用了 fork 创建了子进程,这里返回的 pid 就是 v11. v11 > 0 为父进程,v11 = 0 为子进程。
这里可以看到子进程,也就是 else 中使用了 execl,它提供了一个在进程中启动另一个程序执行的方法,在这里就是启动了当前目录下的 son 文件,然后传递输入的数值 s 作为新进程的参数,同时这里新进程会替换掉之前的子进程,使自身作为父进程的子进程存在。
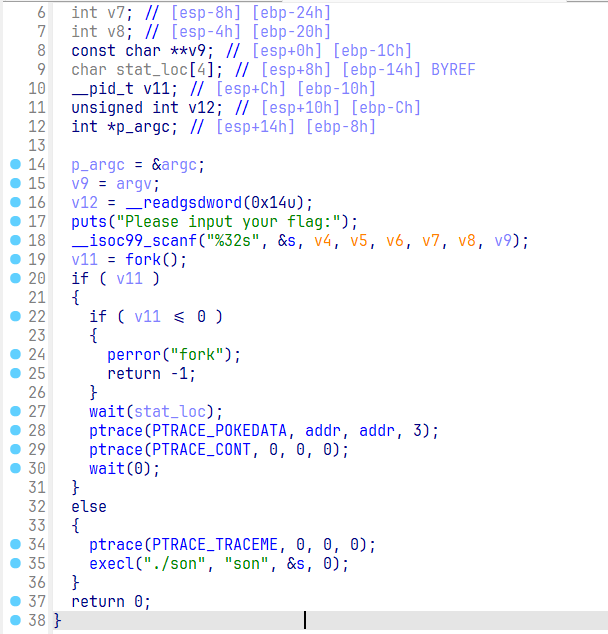
然后查看替换的子进程的内容,打开 son 文件。找到主函数,发现它这里就是把 s 进行移位操作,然后比对内置的数据 byte_60004020。
这里的 s = *(char **)(a2 + 4),它就是指向上面 father 传入的 s. 上面 execl 执行的命令为 ./son s,而对于 son 文件的主函数而言,第一个参数是 a1 表示执行命令参数的个数,这里就是 2,而后面的 a2 真实类型为 const char **argv,它指向的就是命令的各个参数,因此这里的 a2 + 4 执行的就是第二个参数,也就是 s.
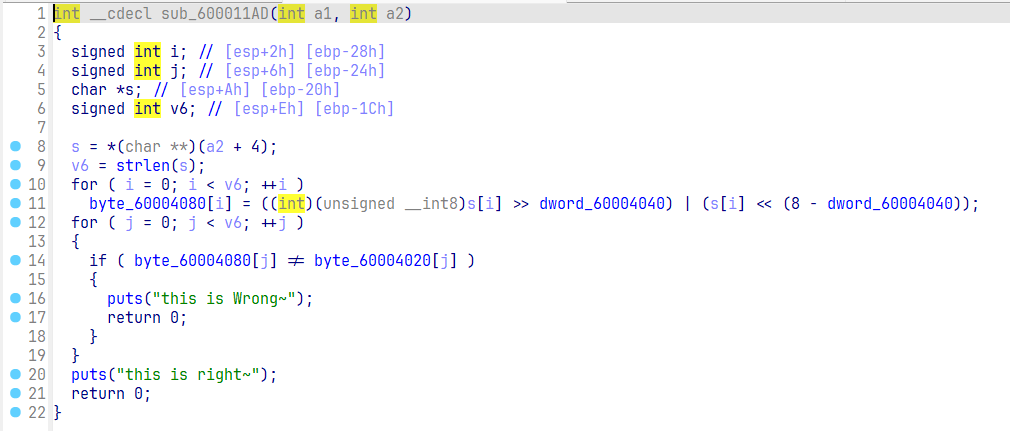
因此目前可以得知它这里的逻辑就是通过 father 来打开 son,通过执行 son 中的每个字节循环移位来进行变化,最后与密文进行比较得到结果。
然后继续关注 father 中的 ptrace,ptrace 是用于进程跟踪的,它提供了父进程可以观察和控制其子进程执行的能力,并允许父进程检查和替换子进程的内核镜像(包括寄存器)的值。而这里查看子进程,可以发现使用ptrace(PTRACE_TRACEME, 0, 0, 0);,它就是允许父进程对自身进行调试的语句,然后在父进程中,使用 PTRACE_POKEDATA 对数据进行修改,然后使用 PTRACE_CONT 让子进程继续执行。因此我们关注的就是父进程对于子进程的什么数据进行了修改。
查看语句 ptrace(PTRACE_POKEDATA, addr, addr, 3);,它就是对于 addr 所指向的地址修行了数据修改,更改为了 3,由此点进去发现 addr 指向的就是 0x60004040 位置的数据 。

然后回想起之前 son 文件的内容,找到了相似的地址。由此可以判断这里修改的就是偏移的数值,把这里的 4 在运行的时候改为了 3。
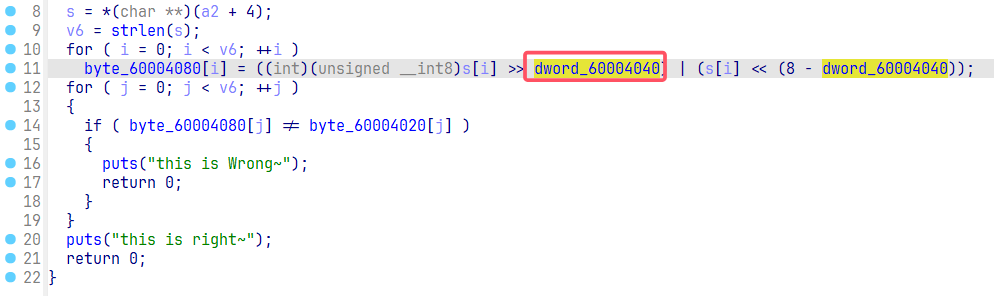
因此得到了整个程序逻辑,在运行时,父进程会更改子进程中偏移量,然后数据的判断就是通过子进程来进行的,所以这里只需要把子进程中的密文按照偏移 3 进行逆变换即可。
python
enc = [204, 141, 44, 236, 111, 136, 237, 235, 47, 237,
174, 235, 78, 172, 44, 141, 141, 47, 235, 109,
205, 237, 238, 235, 14, 142, 78, 44, 108, 172,
231, 175]
for i in range(len(enc)):
enc[i] = (enc[i] << 3 | enc[i] >> 5) & 0xff
print(''.join([chr(e) for e in enc]))drink_tea
逆向的第一步永远都是先用 DIE 查看文件基本信息,发现无壳,文件为 64 位,用 IDA64 打开
主函数的逻辑很简单,就是先判读输入字符串的长度是否为 32,然后再和 key 进入一个加密函数
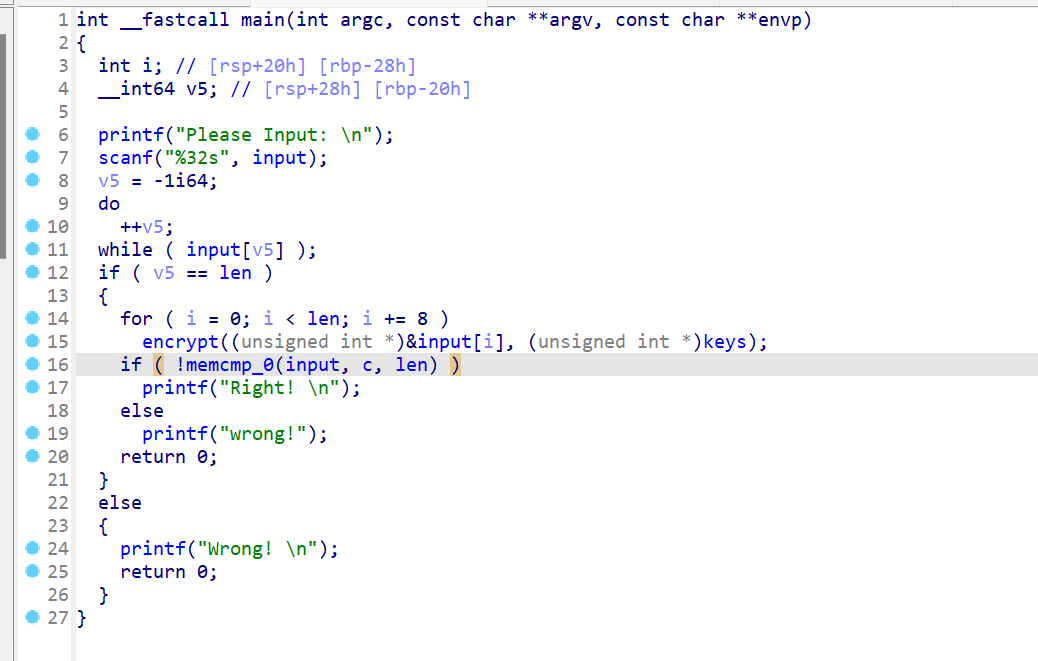
而这个加密就是大名鼎鼎的 TEA 算法,以后我们几乎会在所有比赛看到这个算法以及它的变形
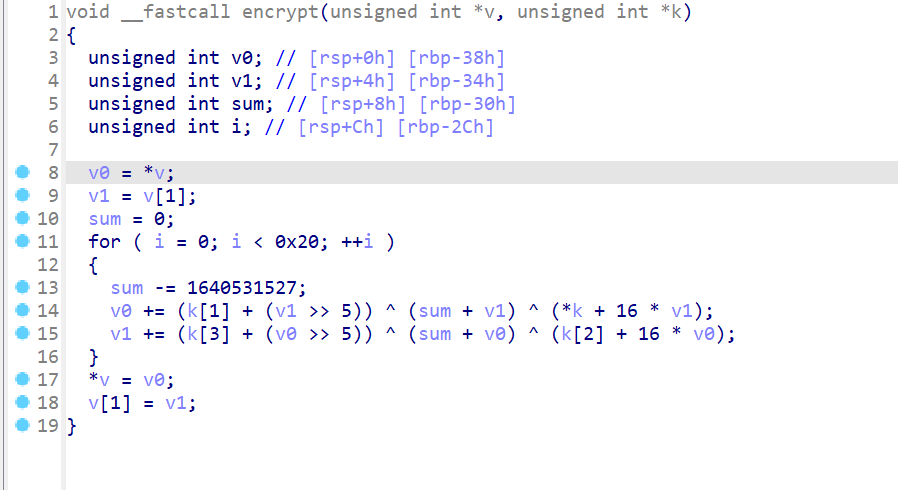
解密脚本:
c
#include <stdio.h>
#include <stdint.h>
//解密函数
void decrypt (uint32_t* v, uint32_t* k) {
uint32_t v0 = v[0], v1 = v[1], i;
uint32_t delta = 2654435769;
uint32_t sum = (32)*delta;
uint32_t k0 = k[0], k1 = k[1], k2 = k[2], k3 = k[3];
for (i = 0; i < 32; i++) { // 解密时将加密算法的顺序倒过来,+= 变为 -=
v1 -= ((v0 << 4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1 << 4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
}
v[0] = v0; v[1] = v1; // 解密后再重新赋值
}
unsigned char keys[] = "WelcomeToNewStar";
unsigned char cipher[] = { 0x78,0x20,0xF7,0xB3,0xC5,0x42,0xCE,0xDA,0x85,0x59,0x21,0x1A,0x26,0x56,0x5A,0x59,0x29,0x02,0x0D,0xED,0x07,0xA8,0xB9,0xEE,0x36,0x59,0x11,0x87,0xFD,0x5C,0x23,0x24 };
int main()
{
unsigned char a;
uint32_t *v = (uint32_t*)cipher;
uint32_t *k = (uint32_t*)keys;
// v 为要加密的数据是 n 个 32 位无符号整数
// k 为加密解密密钥,为 4 个 32 位无符号整数,即密钥长度为 128 位
for (int i = 0; i < 8; i += 2)
{
decrypt(v + i, k);
// printf("解密后的数据:%u %u\n", v[i], v[i+1]);
}
for (int i = 0; i < 32; i++) {
printf("%c", cipher[i]);
}
return 0;
}Dirty_flowers
考查内容是花指令,但是事实上新生在 week2 就学过汇编还是不敢奢望,因此实际考查内容是学习怎么用 nop 改汇编指令。
按下 ⇧ ShiftF12 查找字符串就可以发现提示。
提示说将 0x4012f1~0x401302的指令全部改成 nop 指令,随后在函数头位置按下 U P.
在此不对这段的花指令再进行解释,自己模拟一遍栈帧操作即可理解。
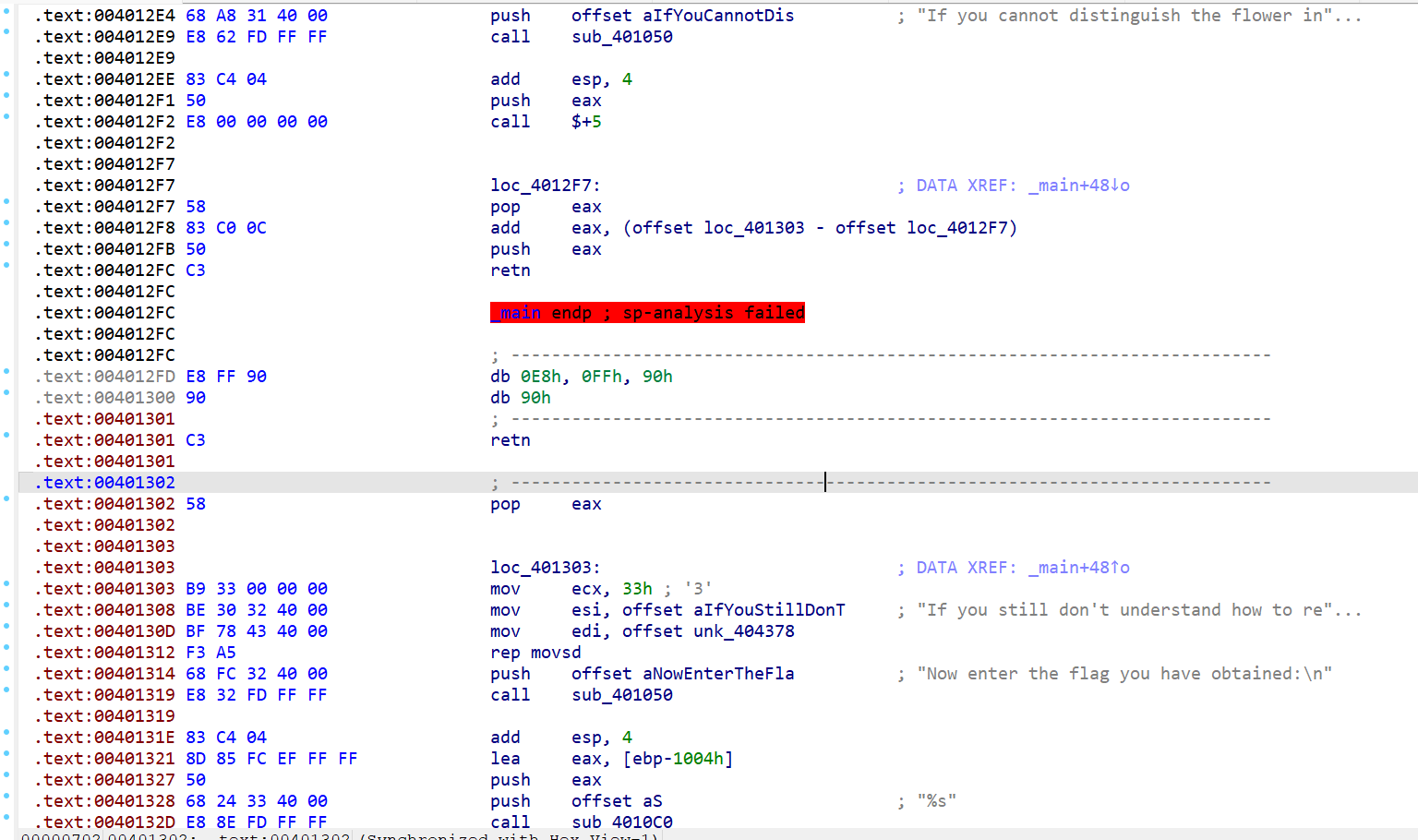
将从 push eax 到 pop eax 这一段全部 nop 掉。
然后在函数头位置按下 U P,再按下 F5,即可正确反编译。
稍微分析一下,将几个函数重命名一下。在函数名位置处按下 N,进行重命名。
基本思路就是先判断长度是否是 36,再进行加密,最后比较。
点进 check 函数可以找到密文,但是点进加密函数却发现 IDA 再次飘红。
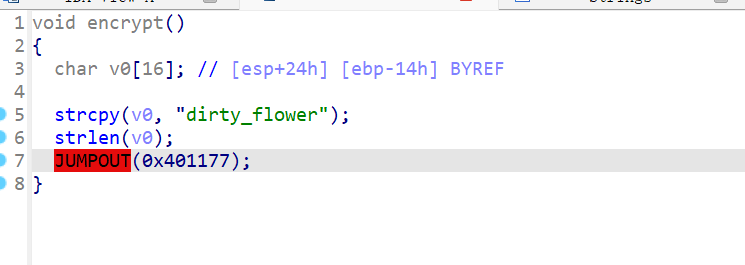
可以很容易发现加密函数里面的花指令与主函数的花指令完全一样。因此再操作一遍即可。
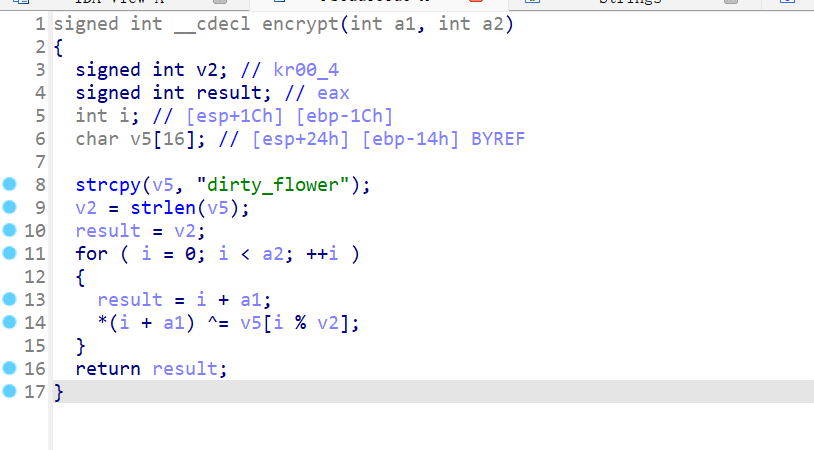
加密函数非常简单。
python
# exp.py
lis = [0x02, 0x05, 0x13, 0x13, 0x02, 0x1e, 0x53, 0x1f, 0x5c, 0x1a, 0x27, 0x43, 0x1d, 0x36, 0x43,
0x07, 0x26, 0x2d, 0x55, 0x0d, 0x03, 0x1b, 0x1c, 0x2d, 0x02, 0x1c, 0x1c, 0x30, 0x38, 0x32,
0x55, 0x02, 0x1b, 0x16, 0x54, 0x0f]
str = "dirty_flower"
flag = ""
for i in range(len(lis)):
lis[i] ^= ord(str[i % len(str)])
flag += chr(lis[i])
print(flag)
# flag{A5s3mB1y_1s_r3ally_funDAm3nta1}